


Building Computer Vision Datasets in Coco Format
A comprehensive tutorial to build custom computer vision datasets


Computer vision is among the biggest disciplines of machine learning with its vast range of uses and enormous potential. Its purpose is to duplicate the brain's incredible visual abilities. Algorithms for computer vision aren't magical. They require information to perform, and they'll only be as powerful as the information you provide. Based on the project, there are various sources to obtain the appropriate data.
The most famous object detection dataset is the Common Objects in Context dataset (COCO). This is commonly applied to evaluate the efficiency of computer vision algorithms. The COCO dataset is labeled, delivering information for training supervised computer vision systems that can recognize the dataset's typical elements. Of course, these systems are beyond flawless, thus the COCO dataset serves as a baseline for assessing the systems' progress over time as a result of computer vision studies.
In this article, we have discussed Coco File Format a standard for building computer vision datasets, object detection, and image detection methods.
Why do neural nets work really well for computer vision?
Artificial neural networks are considered a major subcategory of ML which constitutes the core of deep learning techniques. Their origin and architecture are same as the human mind, and they work like real neurons.
Since pictures do not always have labels, sub-labels for sections and elements must be removed or cleverly reduced, neural networks perform effectively for computer vision. Training information is used by neural networks to train and increase their efficiency with experience. But, once these learning techniques have been fine-tuned for precision, they become formidable resources in computer technology and AI, enabling us to quickly categorize and organize data.
When compared to traditional classification by experienced scientists, activities in voice recognition or image recognition may take only a few minutes rather than hours. Google’s technology is among the most famous neural networks.
Why still there is a need to create a custom dataset
Transfer learning has been a specific technique of machine learning in which a model created for one job is applied as the basis for a model on a different task. Considering the enormous compute as well as time resource base needed to establish neural network systems on such concerns, as well as the large leaps in expertise that they deliver on similar issues, it is a common strategy in machine learning in which pre-trained systems are used as the preliminary step on natural language data processing.
We can deal with these instances using transfer learning, which uses previously labeled data from a comparable task or topic.

Coco File Format is a standard for building computer vision datasets

Photo by Irene Kredenets on Unsplash
Analyzing visual environments is a major objective of computer vision; it includes detecting what items are there, localizing them in 2D and 3D, identifying their properties, and describing their relationships. As a result, the dataset could be used to train item recognition and classification methods. COCO is frequently used to test the efficiency of real-time object recognition techniques. Modern neural networking modules can understand the COCO dataset's structure.
Contemporary AI-driven alternatives are not quite skillful of creating complete precision in findings that lead to a fact that the COCO dataset is a substantial reference point for CV to train, test, polish, and refine models for faster scaling of the annotation pipeline.
The COCO standard specifies how your annotations and picture metadata are saved on disc at a substantial stage. Furthermore, the COCO dataset is an addition to transfer learning, in which the material utilized for one model is utilized to start another.
Tutorial to build Computer vision dataset using Datatorch
Video Tutorial
Datatorch is one of the cloud-based free-to-use annotation tools out there. It is a web-based platform where you can just hop on to and quickly start annotating dataset
Step0: Discovering Data
Solving any machine learning problem first starts with data. The first question is what problem you want to solve. Then the next question is where can I get this data.
In my case (hypothetical), I want to build an ML model that detects different dog breeds from photos. I am sourcing this relatively simple Stanford Dogs Dataset from Kaggle
Step1: Create New Project
After you log in you will see the dashboard main screen showing your projects and organization. This will be good when you are trying to work on multiple projects across different teams.
Now on the top right of the title bar, click on + and create a new project
Step2: Onboard Data
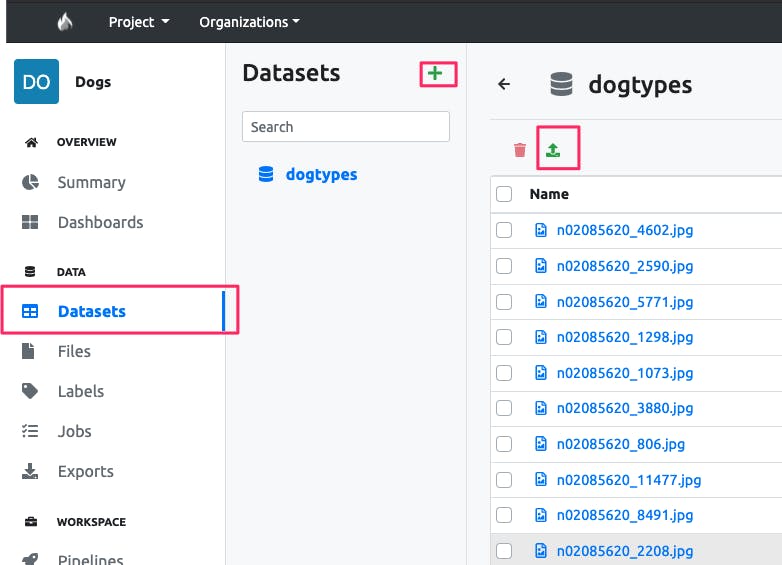
Then go to Dataset tab from the left navigation bar, click on + to create a new dataset named dogtypes. After that you can easily drop the images
Or there is another option to directly connect to a cloud provider storage (AWS, Google, Azure)
Step3: Start Annotating
If you click on any of the image in the dataset, it will directly lead you to the annotating tool
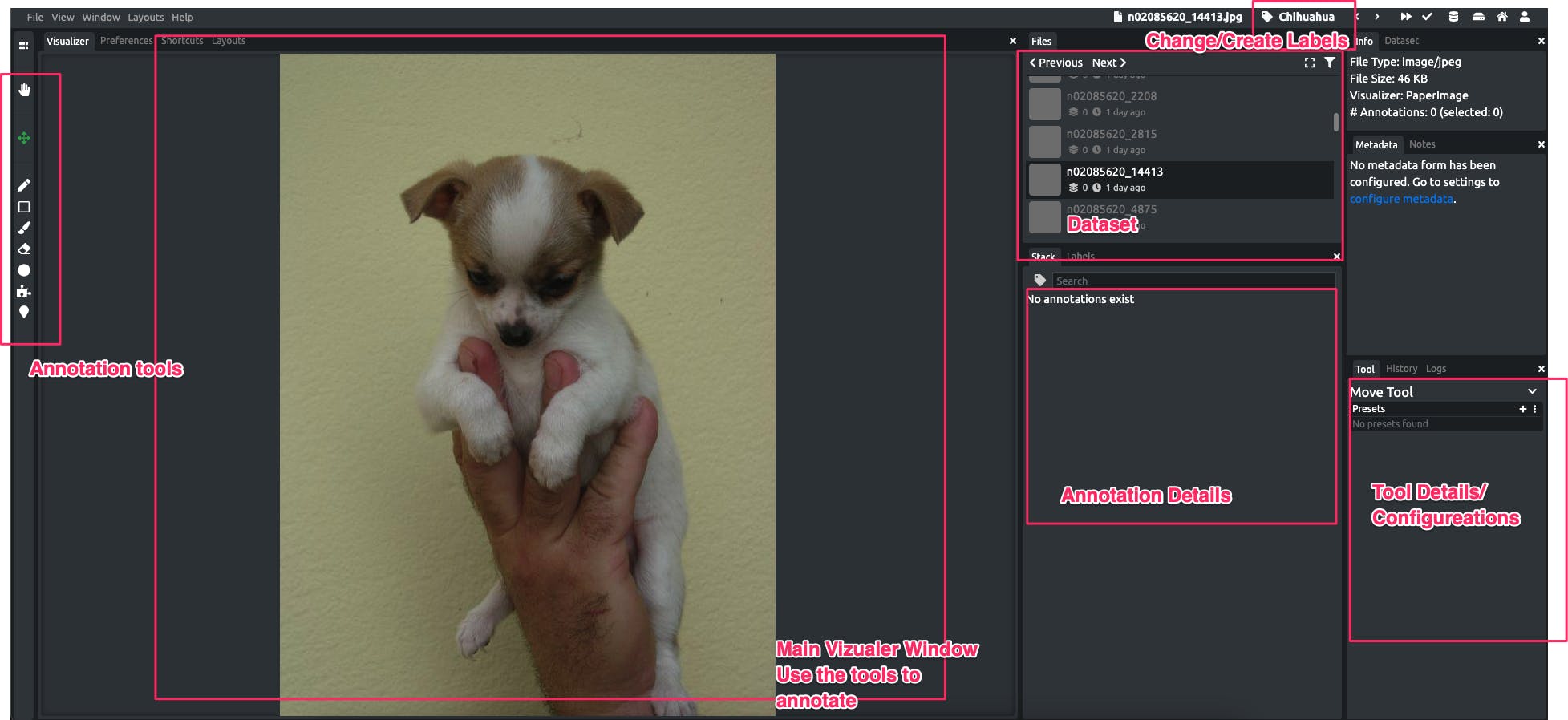
- Annotation Tools On the left there are the annotation tools you can use on the visualizer window in the center
- Dataset: List of all the images, click to annotate them
- Change/Create Labels: Click to change the label associated with annotation
- Annotation Details: After you have done some annotation in the image you will see the details here
- Tool Details/ Configuration: When you select an annotation tool the details/configuration appear on this. For example, if you select a brush tool you can change its size here
To start annotating you can just select an annotation tool from the options, it also depends on the type of model you are trying to build. For an object detection model, something like a bounding box or circle tool is good to use, otherwise for a segmentation model you can use the brush tool or an AI-based superpixel tool to highlight relevant pixels. For example for I just used a simple brush tool (increased the size) to highlight over the dog.
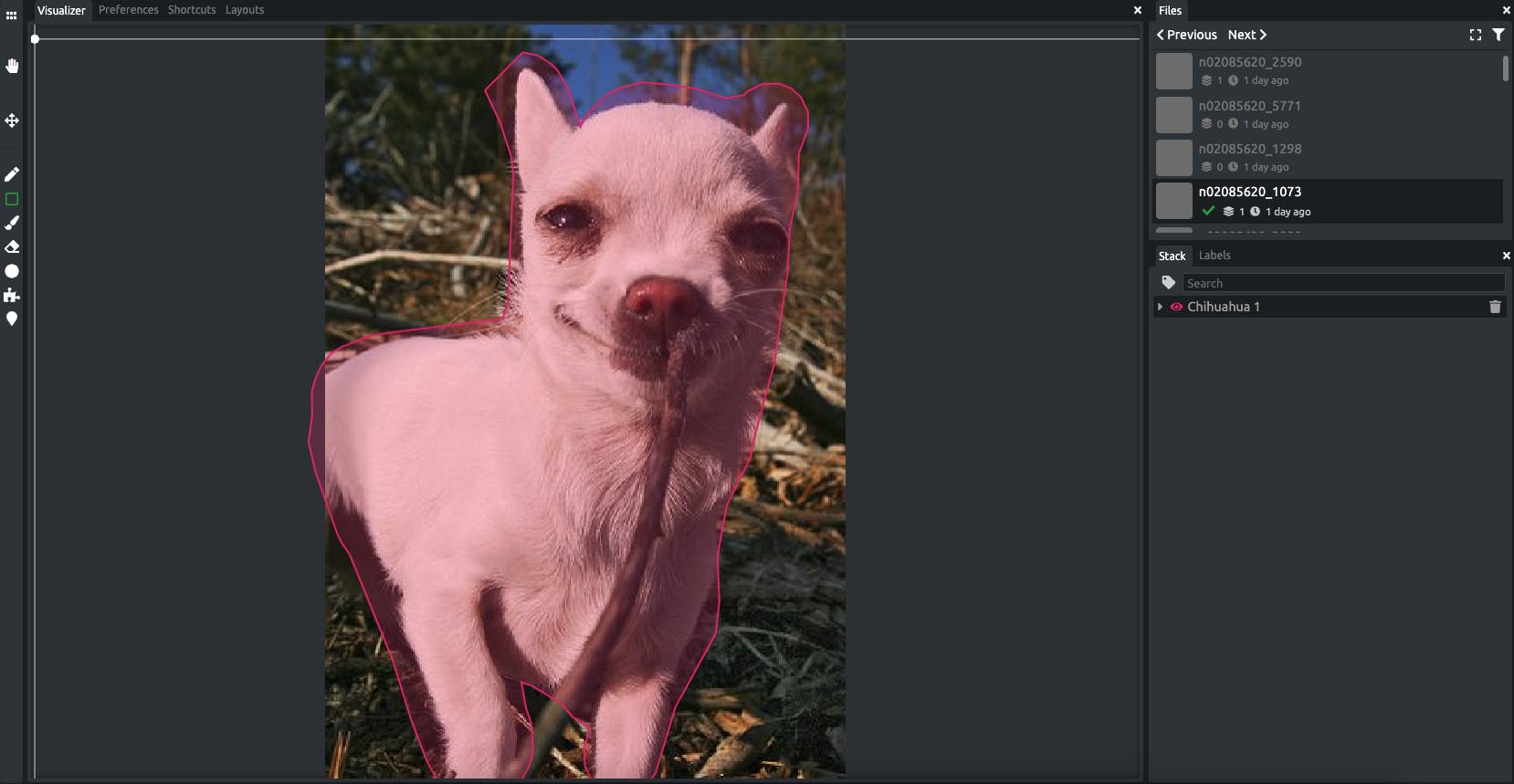
Also, it would be best to discover annotation by trying or you can watch the tutorial on my youtube channel.
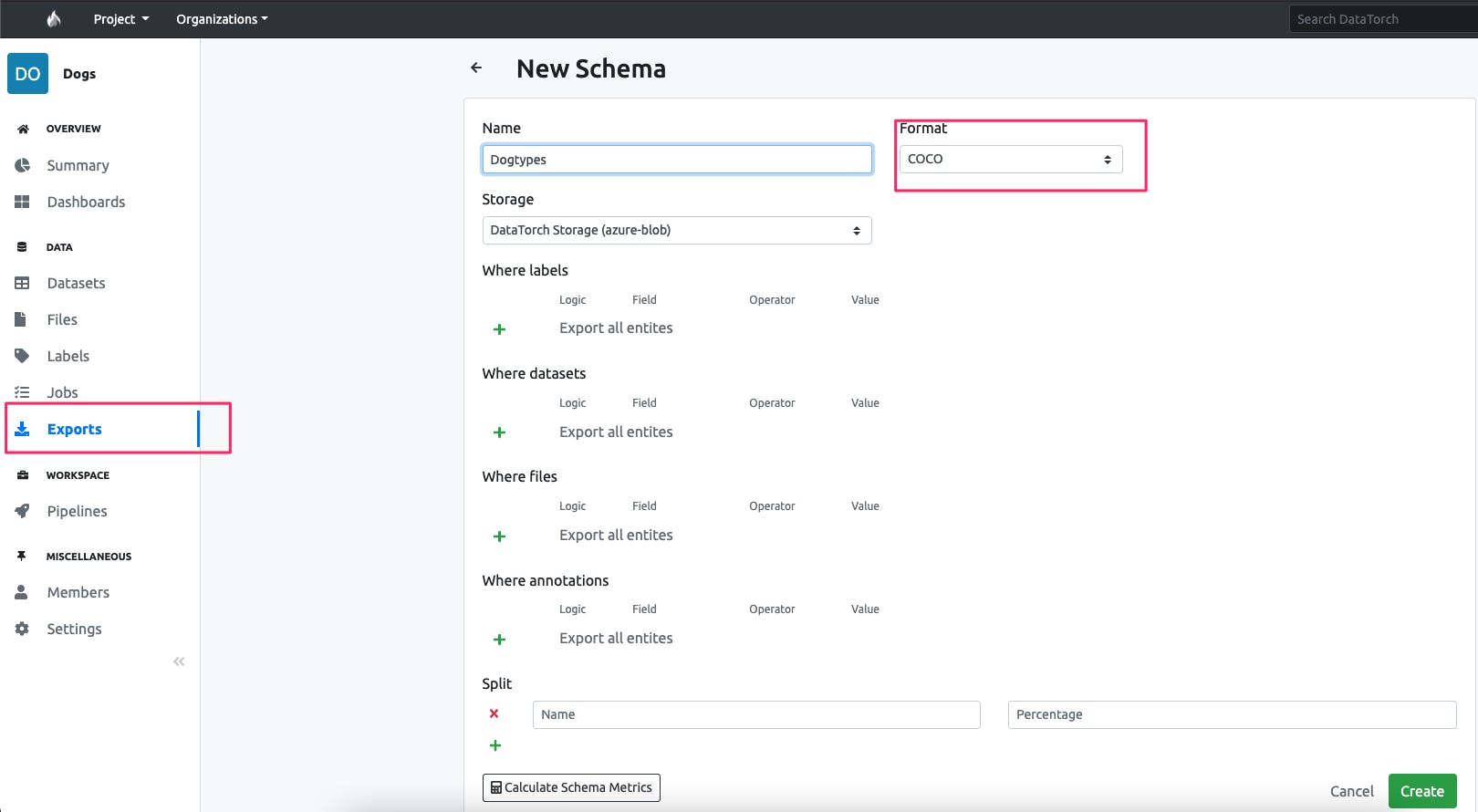
- Step4: Export to Annotated Data to Coco Format After you are done annotating, you can go to exports and export this annotated dataset in COCO format.
Conclusion
If you're inexperienced to object detection and need to create a completely new dataset, the COCO format is an excellent option because of its simple structure and broad use. The COCO dataset structure has been investigated for the most common tasks: object identification and segmentation. COCO datasets are large-scale datasets that are suited for starter projects, production environments, and cutting-edge research.