Spark Streaming with Python
Your guide to getting started with Pyspark Streaming Pipelines

I am a Data Engineer I love Python! I am based in Singapore I have good knowledge on cloud I have some knowledge on building Machine Learning Models I have helped 30+ companies use data effectively I have worked with Petabytes scale of data I write @ TowardsDataScience Nowadays I am focusing on learning Natural Language Processing Ask me about anything, I'll be happy to help.
Apache Spark Streaming is quite popular. Due to its integrated technology, Spark Streaming outperforms previous systems in terms of data stream quality and comprehensive approach.
Python and Spark Streaming do wonders for industry giants when used together. Netflix is an excellent Python/Spark Streaming representation: the people behind the popular streaming platform have produced multiple articles about how they use the technique to help us enjoy Netflix even more. Let's get started with the basics.
What is spark streaming, and how does it work?
The Spark platform contains various modules, including Spark Streaming. Spark Streaming is a method for analyzing "unbounded" information, sometimes known as "streaming" information. This is accomplished by dividing it down into micro-batches and allowing windowing for execution over many batches.
The Spark Streaming Interface is a Spark API application module. Python, Scala, and Java are all supported. It allows you to handle real data streams in a fault-tolerant and flexible manner. The Spark Engine takes the data batches and produces the end results stream in batches.
What is a streaming data pipeline?
It is a technology that allows data to move smoothly and automatically from one location to another. This technology eliminates many of the typical issues that the company had, such as information leakage, bottlenecks, multiple data clash, and repeated entry creation.
Streaming data pipelines are data pipeline architectures that process thousands of inputs in actual time at scalability. As an outcome, you'll be able to gather, analyses, and retain a lot of data. This functionality enables real-time applications, monitoring, and reporting.

Photo by Agence Olloweb on Unsplash
Streaming Architecture of Spark.
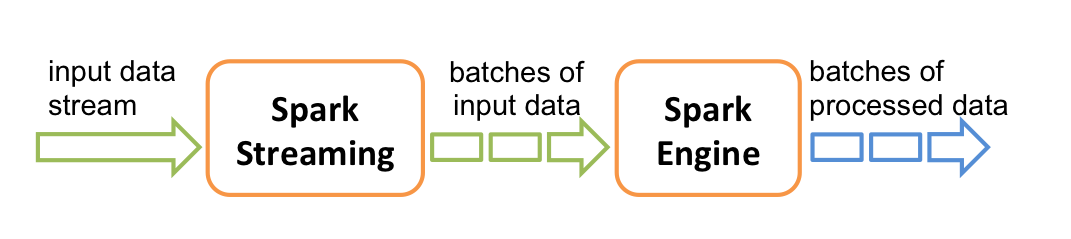
Spark streaming architecture diagram from spark.apache.org
Spark Streaming's primary structure is batch-by-batch discrete-time streaming. The micro-batches are constantly allocated and analyzed, rather than traveling through the stream processing pipelines one item at a time. As a result, data is distributed to employees depending on accessible resources and location.
When data is received, it is divided into RDD divisions by the receiver. Because RDDs are indeed a key abstraction of Spark datasets, converting to RDDs enables group analysis with Spark scripts and tools.
Real-life spark streaming example (Twitter Pyspark Streaming )
In this solution I will build a streaming pipeline that gets tweets from the internet for specific keywords (Ether), and perform transformations on these realtime tweets to get other top keywords associated with it.
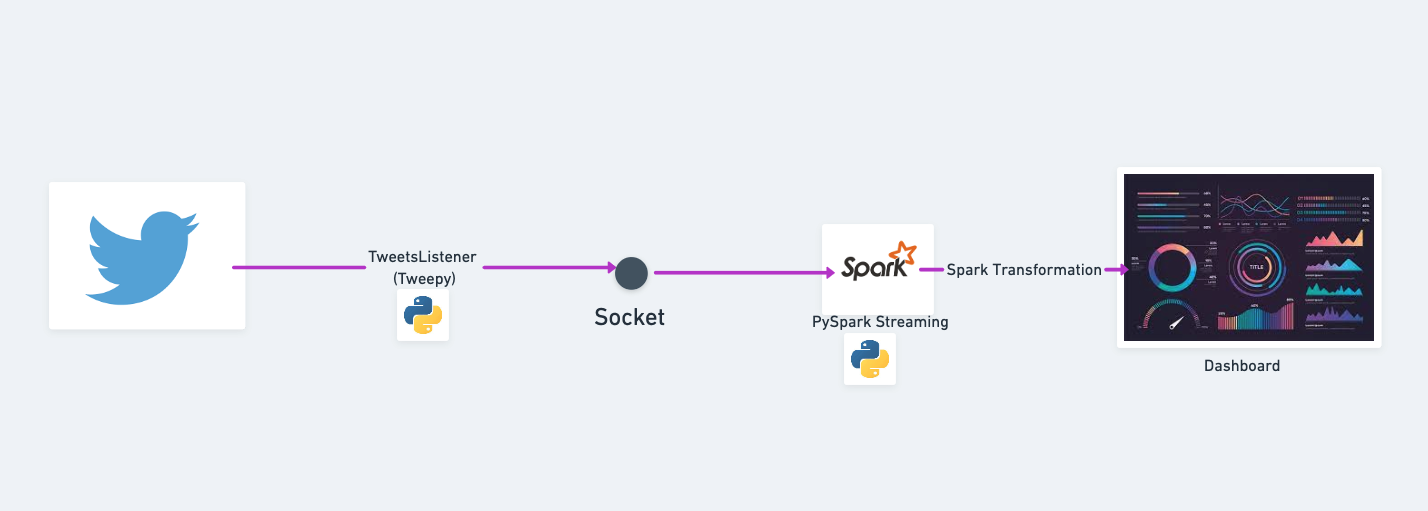
Real-life spark streaming example architecture by the author
Video Tutorial
Step1: Streaming tweets using tweepy
import tweepy
from tweepy import OAuthHandler
from tweepy import Stream
from tweepy.streaming import StreamListener
import socket
import json
# Set up your credentials
consumer_key=''
consumer_secret=''
access_token =''
access_secret=''
class TweetsListener(StreamListener):
def __init__(self, csocket):
self.client_socket = csocket
def on_data(self, data):
try:
msg = json.loads( data )
print( msg['text'].encode('utf-8') )
self.client_socket.send( msg['text'].encode('utf-8') )
return True
except BaseException as e:
print("Error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return True
def sendData(c_socket):
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
twitter_stream = Stream(auth, TweetsListener(c_socket))
twitter_stream.filter(track=['ether'])
if __name__ == "__main__":
s = socket.socket() # Create a socket object
host = "127.0.0.1" # Get local machine name
port = 5554 # Reserve a port for your service.
s.bind((host, port)) # Bind to the port
print("Listening on port: %s" % str(port))
s.listen(5) # Now wait for client connection.
c, addr = s.accept() # Establish connection with client.
print( "Received request from: " + str( addr ) )
sendData( c )
Step2: Coding PySpark Streaming Pipeline
# May cause deprecation warnings, safe to ignore, they aren't errors
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.sql import SQLContext
from pyspark.sql.functions import desc
# Can only run this once. restart your kernel for any errors.
sc = SparkContext()
ssc = StreamingContext(sc, 10 )
sqlContext = SQLContext(sc)
socket_stream = ssc.socketTextStream("127.0.0.1", 5554)
lines = socket_stream.window( 20 )
from collections import namedtuple
fields = ("tag", "count" )
Tweet = namedtuple( 'Tweet', fields )
# Use Parenthesis for multiple lines or use \.
( lines.flatMap( lambda text: text.split( " " ) ) #Splits to a list
.filter( lambda word: word.lower().startswith("#") ) # Checks for hashtag calls
.map( lambda word: ( word.lower(), 1 ) ) # Lower cases the word
.reduceByKey( lambda a, b: a + b ) # Reduces
.map( lambda rec: Tweet( rec[0], rec[1] ) ) # Stores in a Tweet Object
.foreachRDD( lambda rdd: rdd.toDF().sort( desc("count") ) # Sorts Them in a DF
.limit(10).registerTempTable("tweets") ) ) # Registers to a table.
Step3: Running the Spark Streaming pipeline
- Open Terminal and run TweetsListener to start streaming tweets
python TweetsListener.py
- In the jupyter notebook start spark streaming context, this will let the incoming stream of tweets to the spark streaming pipeline and perform transformation stated in step 2
ssc.start()
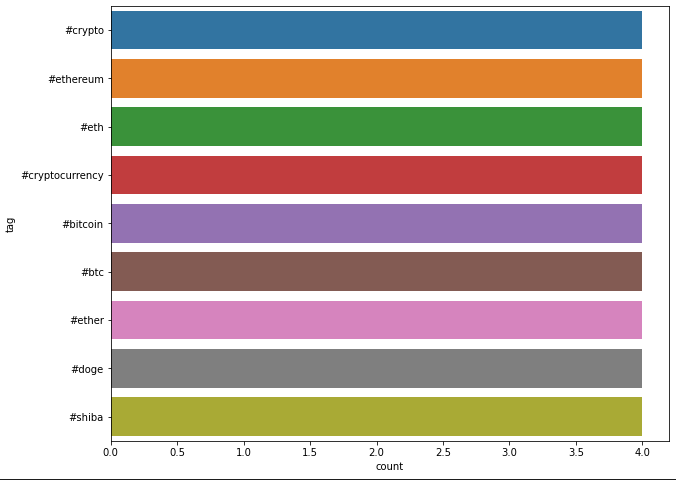
Step4: Seeing real-time outputs
Plot real-time information on a chart/dashboard from the registered temporary table in spark tweets. This table will update in every 3 seconds with fresh tweet analysis
import time
from IPython import display
import matplotlib.pyplot as plt
import seaborn as sns
# Only works for Jupyter Notebooks!
%matplotlib inline
count = 0
while count < 10:
time.sleep( 3 )
top_10_tweets = sqlContext.sql( 'Select tag, count from tweets' )
top_10_df = top_10_tweets.toPandas()
display.clear_output(wait=True)
plt.figure( figsize = ( 10, 8 ) )
# sns.barplot(x='count',y='land_cover_specific', data=df, palette='Spectral')
sns.barplot( x="count", y="tag", data=top_10_df)
plt.show()
count = count + 1
Out:
Some of the pros and cons of Spark Streaming
Now that we have gone through building a real-life solution of spark streaming pipeline, let's list down some pros and cons of using this approach.
Pros
- For difficult jobs, it offers exceptional speed.
- Sensitivity to faults.
- On cloud platforms, it's simple to execute.
- Support for multiple languages.
- Integration with major frameworks.
- The capability to connect databases of various types.
Cons
- Massive volumes of storage are required.
- It's difficult to use, debug, and master.
- There is a lack of documentation and instructional resources.
- Visualization of data is unsatisfactory.
- Unresponsive when dealing with little amounts of data
- There have only been a few machine learning techniques.
Conclusion
Spark Streaming is indeed a technology for collecting and analyzing large amounts of data. Streaming data is likely to become more popular in the near future, so you should start learning about it now. Remember that data science is more than just constructing models; it also entails managing a full pipeline.
The basics of Spark Streaming were discussed in this post, as well as how to use it on a real-world dataset. We suggest you work with another sample or take real-time data to put everything we've learned into practice.




