Are you passionate about using data to create innovative products and solutions? If so, a career as a data engineer may be the perfect fit for you. But what does it take to be successful in this field? In this blog, we will explore the skills and requirements necessary to become a data engineer and succeed in this exciting profession.
To begin with the fundamentals, or say, to build an in-depth understanding, we must start from scratch.
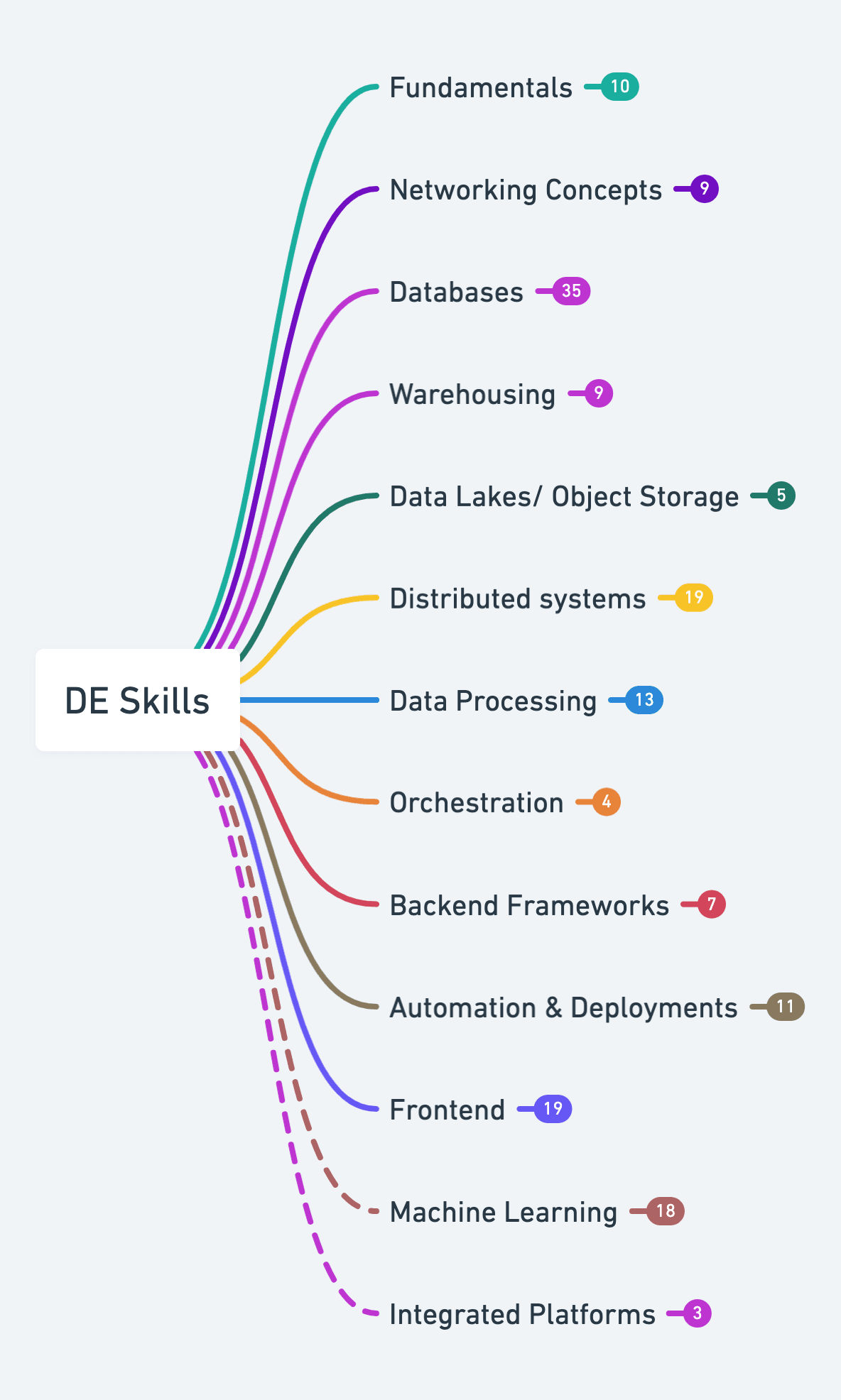
Full visual diagram: Visit this mind map on Whimsical
Fundamental Skills
SQL: Structured Query Language, also called See-Quell, is always at the top of the list for beginners in the domain. The language was developed in 1970 and is the standard language to interact with data in databases.
Almost all the databases and warehouses used a version of SQL as an interactional language.
The popular standard relational databases are MySQL and PostgreSQL. Moreover, other tools and warehouses have adopted SQL as an abstraction, which allows you to build ML models using SQL in big queries.
Programming Language: Next comes the Programming Language. This is the language that engineers begin using to code with and is the central aspect of data engineering. For most of us, Python is the language of choice as it's easier to get started with.
This language comes packed with data science packages and frameworks and is a perfect choice for production code. Alternatively, there are plenty of other languages (such as R, Scala, and Java) that can be used but Python is recommended.
Git: Git is an important tool for version control, which is a practice of tracking and managing changes to software code. As for every single change that you perform, that change becomes a part of your code base in some remote server/cloud.
But how does Git help you? Git lets you save all the changes and actions that you take while coding and this works wonderfully while collaborating with your team, without losing your code. You just need to simply create a new branch and send a pull request to merge code and Voila! You’re ready to collaborate and work on your code. Check out my video tutorial on git if you want to get started with this technology
Complete Git and GitHub Tutorial for Beginners (Data Professionals)
Linux Commands & Shell Scripting: Being a practitioner in the world of data engineering, you would mostly be dealing with a Linux VM or Server. No matter if in a public cloud or a private server, these machines inherently use some version of Linux such as Ubuntu, Fedora, etc.
Therefore, to work with such machines, you are required to have some knowledge of commands to navigate with Linux servers. Some of the basic commands such as cd, pwd, cp, and mv are a good start, and much more to learn further. However, Shell Scripting is a great tool to automate these Linux commands, without needing to manually use these commands.
Data Structure & Algorithm: Next in the line is Data Structure and Algorithm. Even though you will not be required to create data structures on your own, it is still required for an aspiring data engineer to have an adequate understanding and problem-solving skills of DS & Algo (similar to software engineering). For this purpose, Easy- Intermediate-level LeetCode problems will be enough for the initial practice.
Concept of Networking
As a data engineer, you would be responsible for quite a lot of deployments to VMs and servers. Therefore, It is important for someone dealing with VMs (Virtual Machines), Servers, and APIs (Application Programming Interfaces) to have a basic understanding of basic networking concepts such as IP (Internet Protocol), DNS (Domain Name Server), VPN, TCP, HTTP, Firewalls, etc.
Databases
Fundamentals: A database is a space where data is stored. You will be interacting with many of these databases as a data engineer. For this reason, you need to understand the fundamental concepts of databases, such as tables, rows, columns, keys, joins, merges, and schema.
SQL: This was supposed to be covered once again when talking of the databases, as it comes in handy as an interactional language when working with these databases.
ACID: This abbreviation stands for Atomicity, Consistency, Isolation, and Durability. This is a set of properties of database transactions intended to guarantee data validity, despite errors, power failures, and any other such mishaps.
Database Modelling: Data Modelling or Schema Design helps extensively when building any database, be it applications or warehouses. That is why it is essential to have some knowledge of design patterns for creating schemas for databases. This includes star schema, flat design, snowflake model, etc.
Database Scaling: Vertical Scaling refers to the increase of configuration of a single machine where the database is deployed, which can also be scaled up later on. Alternatively, for Horizontal scaling also known as Sharding, you perform the same process to store the data but, into multiple machines.
OLTP Vs. OLAP: OLTP (Online Analytical Processing) & OLTP (Online Transaction Processing) are two different types of data processing systems. Complex queries are used by online analytical processing (OLAP) to examine past data that has been collected from OLTP systems.
Relational Databases: These are traditional-style databases that power most of the applications. a single database can contain multiple tables with rows and columns. The most commonly used databases of this kind are PostgreSQL and MySQL.
Non-Relational Databases: Non-Relational Databases store the data as nodes and relations separately using a storage model, instead of a tabular schema. This helps in storing the data systematically and then promptly extracting and fetching the data records. Non-relational data further comes in three different types that can be understood well as and when needed.
Key-Value Databases: examples are Redis, DynamoDB, and FireBase
Graph Database: examples are Neo4j and ArangoDB
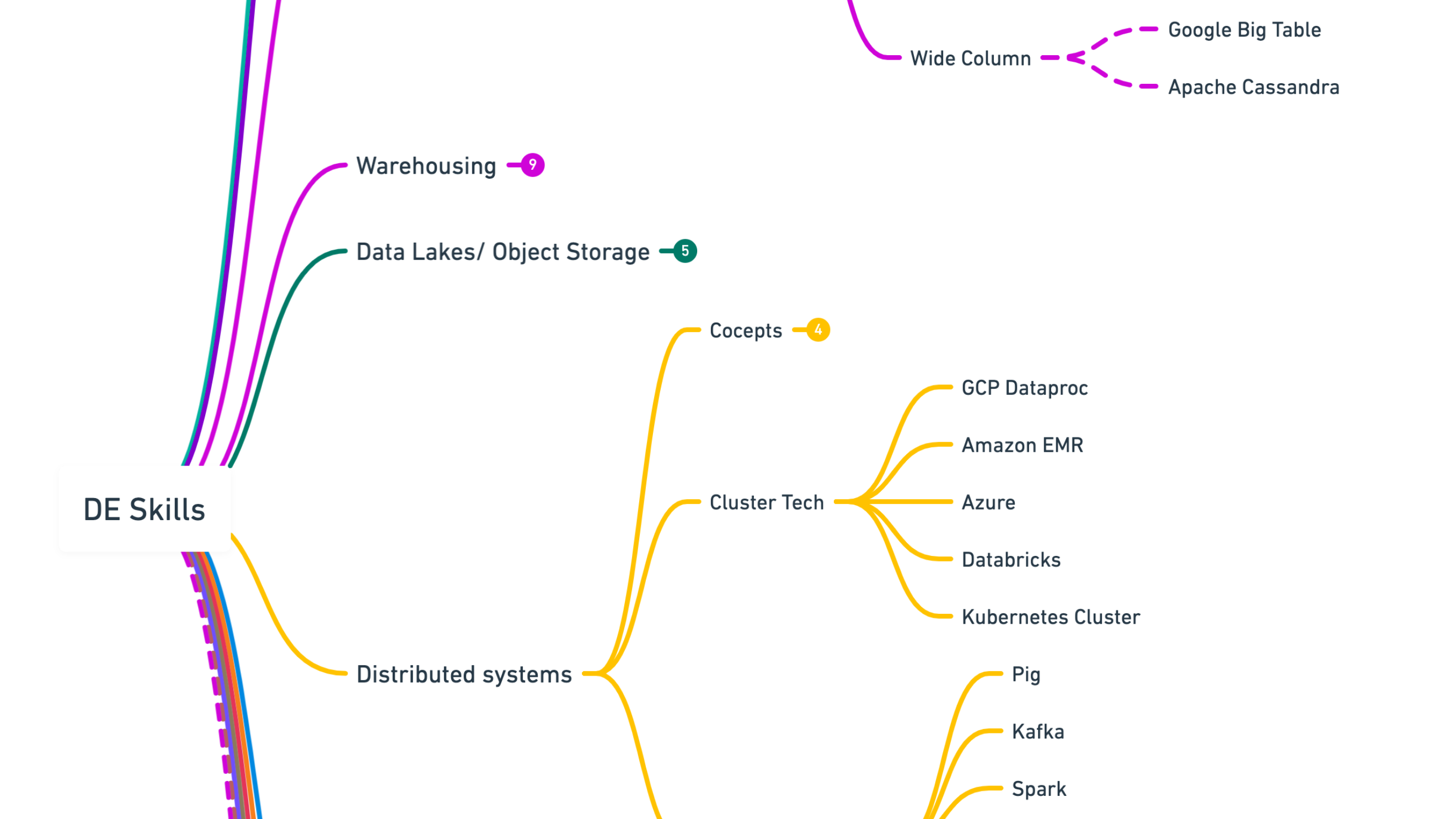
Wide Column Databases: examples are Apache Cassandra, and Google BigTable
Data Warehousing
The inability of databases to store a huge amount of data leads us to a warehouse. These data warehouses can store large volumes of current and historical data for query and analysis. Data Warehousing is simply databases designed with analytical workloads in mind. These are powerful enough to perform complex aggregate queries and transformations to yield insights. Some of the key concepts to understand within warehousing are-
SQL: With the advent of powerful data warehouses that abstract away complexity, proficiency in SQL is all that is required to unlock their full potential.
Normalization Vs. Denormalization: Normalization involves removing redundancy or any inconsistencies in the data. While Denormalization is the technique of merging the data into a single table to improve data change speeds.
OLAP Vs. OLTP: The primary distinction between the two is that one uses data to gather important insights while the other supports transaction-oriented applications.
Some of the popular data warehouses are:
Google’s Big Query
AWS Redshift
Azure Synapse
Snowflake
ClickHouse
Hive
Data Lakes/Object Storage
These work as file storage sources where you can store your files or blob files. They are huge cloud networks that are used globally and are readily available to you.
Distributed Systems
When multiple machines work together as a cluster, they form Distributed Systems. These systems are used when the data is huge and cannot be managed by a single machine. They have separate sets of technologies due to their own complexities. Some of the concepts you must know in depth-
Big Data
Hadoop
HDFS
Map Reduce
Some of the technologies that are built for this purpose include Cluster technologies like Kubernetes, Databricks, Custom Hadoop Cluster, etc. Open-source technologies are also available in distributed systems.
Data Processing
This is where your coding skills will come to use for transforming the data as the raw data is never usable. Being a data engineer, your job responsibility will mainly revolve around transforming the data to be served in the right format. This further includes cleaning the data and its validation. Panda can be your first-hand tool to perform this process as it’s an easy-to-use python package that uses data frames. SQL can also be used to transform big data as most of the data warehouses support this language. Spark is the most popular framework used for big data transformation. Similarly for stream processing Spark Streaming is the preferred choice.
Orchestration
Orchestration is used to schedule and orchestrate jobs and create pipelines and workflows. The best tool for orchestration is Airflow, as it uses python-based Direct Acrylic Graphs to write down the workflow of jobs. From the simplest of tasks to the most complex ones, Airflow can create everything. Some other orchestration tools are Luigi, Nifi, and Jenkins.
Backend Frameworks
It can be assumed by the name itself that Backend frameworks somehow overlap with software engineering. Backend Frameworks come to use when you require to serve some data set, model, or functionality to be used by some application. For this task, you will be needed to create the backend APIs/frameworks such as Flask, Django, and FastAPI. Some of the dedicated technologies based on python are Flask, Django, and FastAPI. Some of the cloud-based technologies are GCP Vertex AI API for model deployments and Automl APIs.
Frontend & Dashboarding
Frontend and exploration technologies are about displaying the results and actions performed through charts, images, and diagrams. There are plenty of tools available which might not come to use for a data engineer but are good to know about. The popular ones are Jupyter Notebooks, Dashboarding (PowerBI, Tableau), Python Frameworks (Dash, Gradio), etc.
Automation & Deployments
Automation and Deployments are about automating and deploying the codes using a variety of tools and technologies. A few of the important technologies include the following:
Infrastructure as code: Using Terraform, Ansible, Shell Scripts
CI/CD: Using GitHub Actions, Jenkins
Containerization: Docker, Docker Compose
Machine Learning
Machine Learning algorithms (or models) are just another great concept to gain knowledge about. Machine learning is majorly used by data scientists to make predictions by analyzing current and historical data. However, data engineers must have a strong understanding of the basics of machine learning as it can naturally enable them to deploy models, as well as build pipelines having more accuracy. This directly benefits the data scientists to make precise decisions. Hence, it is good to understand the fundamentals and frameworks of ML. Some of the platforms used for ML Operations are Google AI Platforms, Kubeflow, and Sagemaker.
Integrated platforms allow data scientists and data engineers to have integrated workflows together in one place. AWS Sagemaker, Databricks, and Hugging Face, are some examples of Integrated Platforms,
Conclusion
In the field of data engineering, there are a myriad of skills that one needs to learn, and that requires gaining hands-on experience too. As an aspiring data engineer, you get to choose from a wide variety of skills and tools to work with, and that’s the thrill of it all!
For more information and elaborative understanding, you can check out the video below!
DATA ENGINEERING SKILLSET