A Step-by-Step Roadmap To Data Engineering
Navigating the Data Engineering Landscape: A Comprehensive Guide
I am a Data Engineer I love Python! I am based in Singapore I have good knowledge on cloud I have some knowledge on building Machine Learning Models I have helped 30+ companies use data effectively I have worked with Petabytes scale of data I write @ TowardsDataScience Nowadays I am focusing on learning Natural Language Processing Ask me about anything, I'll be happy to help.
The specialized field of data engineering is ever-expanding and its elements of it are scattered all around. But how do we come to grips with not being confused & consumed in the process of learning?
Initially, you must follow a roughly drawn map and leave the rest to the skills and opportunities you opt for. A fun way to understand this roadmap is to imagine a smooth transition from a rookie to a professional data engineer with each sprint you take!
/
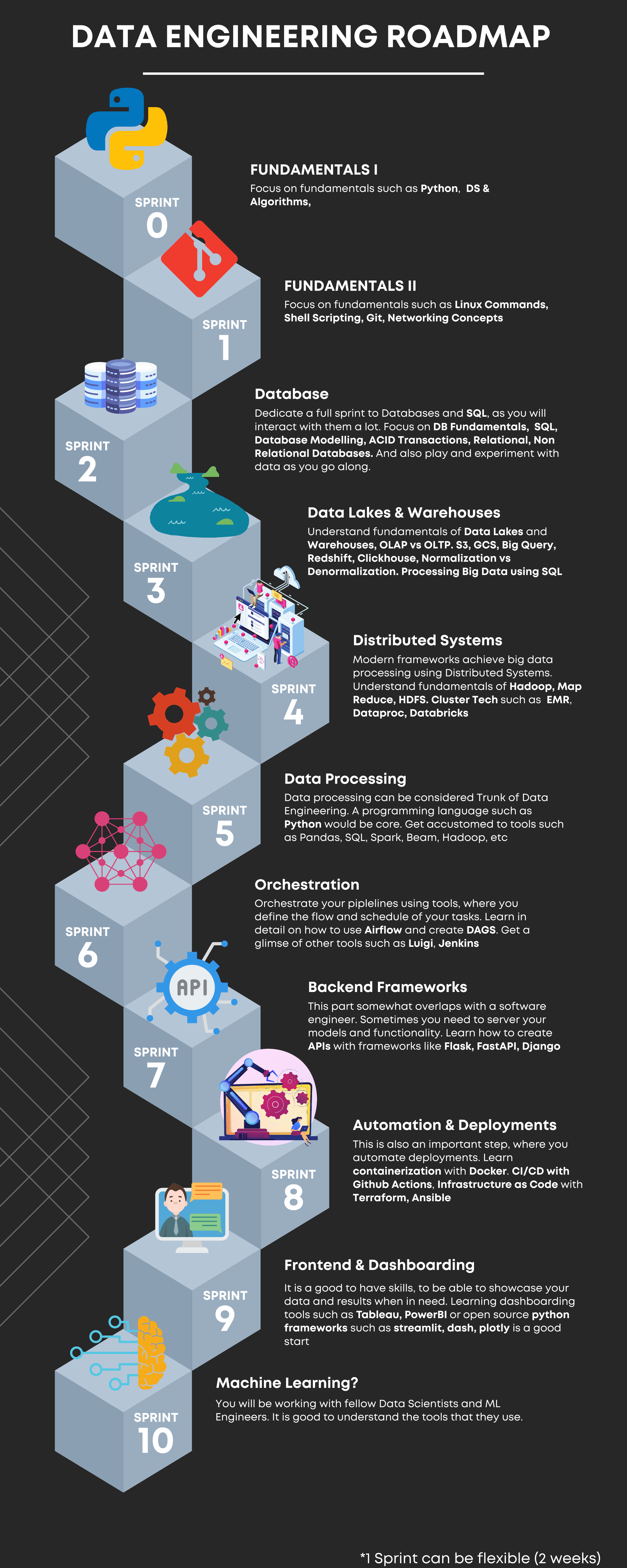
Sprint 1: Strengthening the Base Level
Fundamentals I: Focus on fundamentals such as Python, DS & Algorithms
Firstly, you must focus on fundamental skills such as Python, Data Structures & Algorithms. These programming languages will be used to interact when working with various types of databases. That is why they are also known as interactional languages. At this step, it will be a fruitful decision to learn about data structures and algorithms as it holds most of the things that you will come across regularly later.

Although object-oriented languages such as Python have in-built data structures and assorted open source packages for the application of algorithms. However, it is still preferred to have a better understanding of data structures and algorithms as they help in writing optimized code.
Fundamentals II: Linux Commands, Shell Scripting, Git, Networking Concepts

Next in the fundamentals comes a mixed combination of skills like Linux commands, Shell Scripting, Git, and Networking Concepts. These are important for times when you will be dealing with virtual/cloud servers and several other platforms to transform, manage, and store the data.
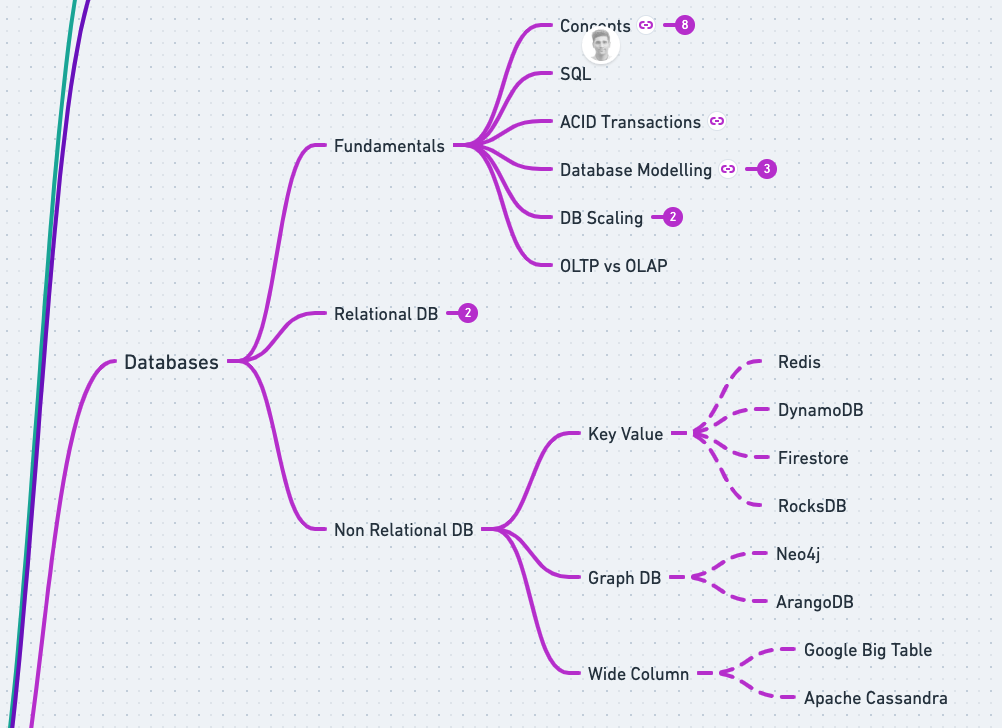
Sprint 2: Database

A full sprint dedicated to databases and SQL, as you will have maximum interaction with them in this journey. You need to focus on Database Fundamentals, SQL, Database Modelling, ACID Transaction, Relational, and Non-Relational Databases. Here, you are free to play and experiment with data as you go along and build a good understanding of these concepts.
Sprint 3: Data Lakes & Warehouses
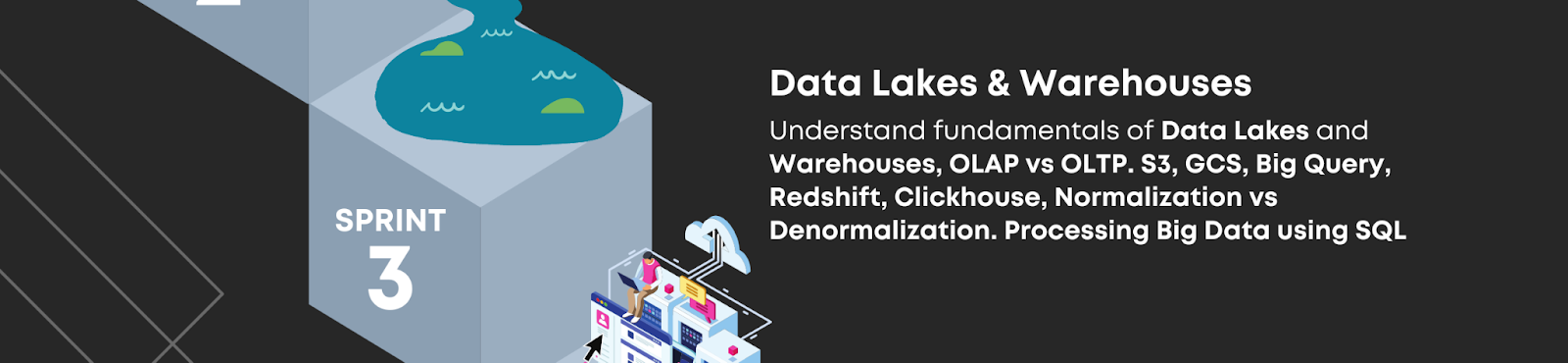
Understand fundamentals of data lakes and warehouses, OLAP Vs. OLTP, S3, GCS, Big Query, Redshift, ClickHouse, Normalization Vs. Denormalization, and processing Big Data using MySQL. These concepts demand dedicated attention from the learners as they play a major role when storing data and managing it all in different places for different purposes.
Sprint 4: Distributed Systems
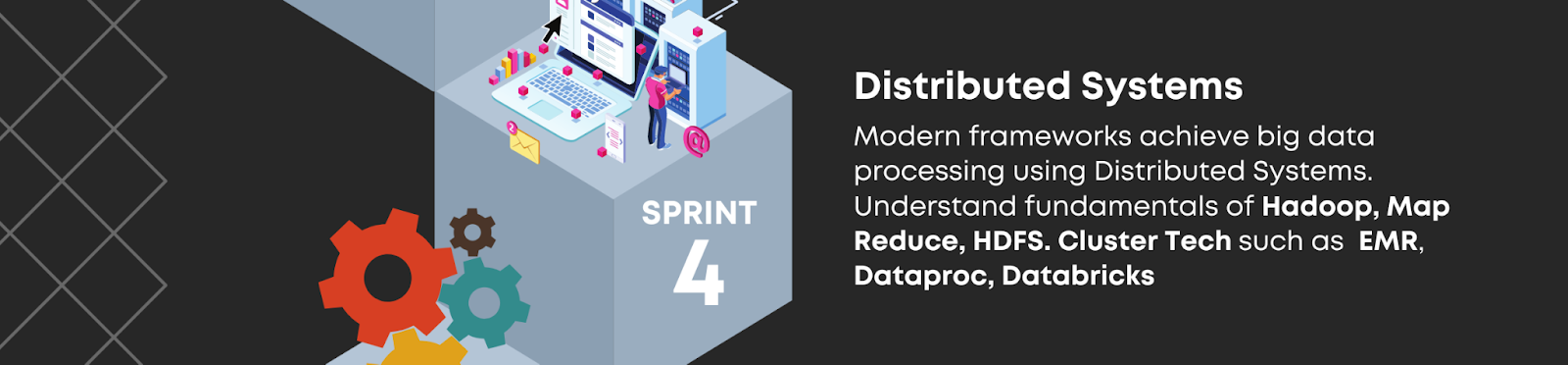
Distributed Systems are formed when multiple machines work together in groups to manage massive data sets which cannot be done by a single machine alone. These modern frameworks achieve big data processing using Distributed Systems. Hence, it is required to understand the fundamentals of Hadoop, Map Reduce, HDFS, and Cluster Tech such as EMR, Dataproc, and Databricks.
Sprint 5: Data Processing

Data Processing is a step where your coding skills will be challenged. Why? Because it will be required to transform the raw data to bring the most of its utility. A programming language such as Python is a must-have as a coding language that is mostly used. It is suggested that you get accustomed to a variety of tools such as Pandas, SQL, Spark, Beam, Hadoop, etc.
Sprint 6: Orchestration

With the sixth sprint you will take, you need to learn to orchestrate the pipelines using tools, where you define the flow and schedule of your tasks. But that’s not just it! It is needed that you gain a detailed understanding of how to use Airflow and create DAGS (Direct Acrylic Graphs). Also, get a glimpse of other orchestration tools such as Luigi and Jenkins.
Sprint 7: Backend Frameworks

This part of the concept in data engineering overlaps with that of software engineering. Sometimes you need to serve your models and their functionality. Therefore, it is crucial to be well aware and learn how to create APIs with frameworks such as Flask, FastAPI, and Django.
Sprint 8: Automation & Deployments

This kind of technology is important to understand as it lets you automate and deploy the codes using a variety of tools and platforms. For you, a few of the necessary learning technologies would be Containerization with Docker, CI/CD with GitHub Actions & Infrastructure as code using Terraform and Ansible.
Sprint 9: Frontend & Dashboarding

Frontend and exploration technologies are essential tools when it comes to showing the outcomes and actions taken on large data sets. In other words, they help visualize the ongoing changes and results using charts, graphs, and diagrams. Some of the popular tools to get used to are Jupyter Notebooks, Dashboarding tools such as PowerBI & Tableau, and Python frameworks such as Dash & Plotly, etc.
Sprint 10: Machine Learning

At this point, you’re already competent enough in the field of data engineering. However, to work as a professional alongside a team of other engineers, data scientists, and analysts, It is necessary to grasp the concepts of Machine Learning. ML models and algorithms are used by data scientists to study and then make calculative predictions that can benefit business organizations to make big decisions.
Conclusion
An in-depth understanding of the core concepts is the first step when learning any subject as it promises you great success. Likewise, it is imperative to go with a clear and succinct approach in the advancing field of Data Engineering. This roadmap has simple guiding steps to ensure you can build a promising career with undying enthusiasm. The aspirants of data and its engineering must indulge in learning and practicing from a wide array of skills and technologies as time passes.
For more information and elaborative understanding, you can check out the video!




