Dask: A Scalable Solution For Parallel Computing

I am a Data Engineer I love Python! I am based in Singapore I have good knowledge on cloud I have some knowledge on building Machine Learning Models I have helped 30+ companies use data effectively I have worked with Petabytes scale of data I write @ TowardsDataScience Nowadays I am focusing on learning Natural Language Processing Ask me about anything, I'll be happy to help.
Bye-bye Pandas, hello dask!
 on [Unsplash](https://unsplash.com/s/photos/processor?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://cdn-images-1.medium.com/max/12056/1*VZ5ZAHRxhSYZaw3w8a8JNw.jpeg) Photo by Brian Kostiuk on Unsplash
Photo by Brian Kostiuk on Unsplash
For data scientists, big data is an ever-increasing pool of information and to comfortably handle the input and processing, robust systems are always a work-in-progress. To deal with the large inflow of data, we either have to resort to buying faster servers that adds to the costs or work smarter and build custom libraries like Dask for parallel computing.
Before I go over Dask as a solution for parallel computing, let us first understand what this type of computing means in the big data world. By the very definition, parallel computing is a type of computation where many calculations or the execution of processes are carried out simultaneously. To simplify, parallel computing refers to getting a computational task done by multiple task doers (or processors) which are connected through a shared memory.
So what is Dask?
Written in Python, Dask is a flexible, open-source library for parallel computing. It allows developers to build their software in coordination with other community projects like NumPy, Pandas, and scikit-learn. Dask provides advanced parallelism for analytics, enabling performance at scale.
Dask is composed of two parts: Dynamic task scheduling for optimized computation and Big Data collections such as like parallel arrays, dataframes, and lists that extend common interfaces like NumPy, Pandas, or Python iterators to larger-than-memory or distributed environments, which run on top of dynamic task schedulers.
Why Dask?
One might argue the need to switch to Dask with other equivalents present. However, the biggest virtue of Dask is that it is easy to adopt. It is familiar for Python users and uses existing APIs and data structures, making it a seamless process to switch between NumPy, Pandas, scikit-learn to their Dask-powered equivalents — all without requiring you to completely rewrite your code or retrain the software to scale.
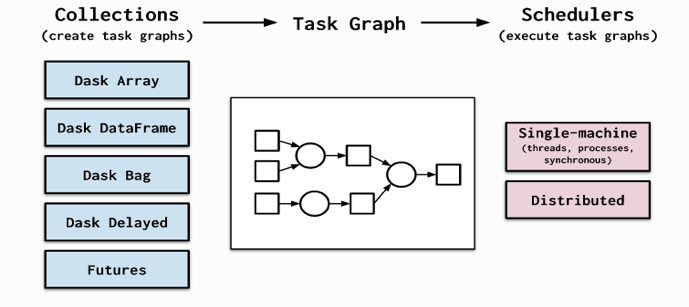
In addition to offering familiarity, Dask is:
Flexible: Using Dask allows for custom workloads and integration with other projects.
Native: Dask natively scales Python with distributed computing and access to the PyData stack.
Agile: Low overhead, low latency, and minimal serialization, Dask offers impressive agility for numerical algorithms
Scalable: Dask can scale up on clusters with 1000s of cores and scale down to set up and run on a laptop in a single process!
Responsive: With interactive computing in consideration, Dask provides rapid feedback and diagnostics to aid humans.
Dask and Big Data
While Pandas is a powerful tool for data computation and analysis, Dask succeeds it with its capability to handle volume of data larger than your local RAM without overwhelming the system or compromising the performance. It provides an easy way to handle large and big data in Python without requiring extra effort.
Given the current situation of working from home, having to tag along bigger machines is not exactly the definition of flexible working. This is where Dask’s power and convenience of functioning seamlessly on a laptop comes into play. It installs trivially with conda or pip and extends the size of convenient datasets from “fits in memory” to “fits on disk”.
 on[ Unsplash](https://unsplash.com/s/photos/big-data?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)*](https://cdn-images-1.medium.com/max/2000/1*2w38VyB_e6SOrmnCuJLjsQ.png) Photo by
Photo byAs explained, Dask is resilient, elastic, data local, and low latency. The ease of transition lets you seamlessly move between single-machine to moderate cluster. For those already familiar with Pandas, Dask will seem like an extension in terms of performance and scalability. You can switch between a Dask dataframe and Pandas dataframe on-demand for any data transformation and operation.
Examples | Dask Dataframes Basics
Dask Dataframes coordinate many Pandas dataframes, partitioned along an index.

- Create a random Dataset
**import** **dask**
**import** **dask.dataframe** **as** **dd**
df = dask.datasets.timeseries()
Output: Dask DataFrame Structure:
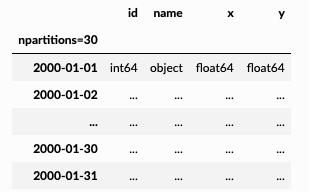
- Load data from flat files
We can load multiple
csvfiles intodask.dataframeusing theread_csvfunction. This supports globbing on filenames, and will sort them alphabetically. This results in a singledask.dataframe.DataFrameof all data
**import** **dask.dataframe** **as** **dd**
df = dd.read_csv('employee_*.csv').set_index('id')
- Perform transformations
Dask dataframe follows the pandas api. We can perform arithmetic, reductions, selections, etc... with the same syntax used by pandas.
The main difference is that we’ll need to add a .compute() to our final result.
df2 = df[df.y > 0]
df3 = df2.groupby('name').x.std()
df3
Output:
Dask Series Structure:
npartitions=1
float64
...
Name: x, dtype: float64
Dask Name: sqrt, 157 tasks
Call compute
computed_df = df3.compute()
computed_df
- Plot output
**from** **matplotlib** **import** pyplot **as** plt
%matplotlib inline
df.A.compute().plot()
Output:
Examples | Working with a real dataset (NYCTaxi 2013)
In 2014 Chris Whong successfully submitted a FOIA request to obtain the records of all taxi rides in New York City for the year of 2013.
#Downloading and unzip
!wget [https://storage.googleapis.com/blaze-data/nyc-taxi/castra/nyc-taxi-2013.castra.tar](https://storage.googleapis.com/blaze-data/nyc-taxi/castra/nyc-taxi-2013.castra.tar)
#Reading data from files
import dask.dataframe as dd
df = dd.from_castra('tripdata.castra/')
df.head()
#Setup progress bar
from dask.diagnostics import ProgressBar
progress_bar = ProgressBar()
progress_bar.register()
Sample Computations
#**How many passengers per ride?**
df.passenger_count.value_counts().compute()
#How many medallions on the road per day?
%matplotlib inline
df.medallion.resample('1d', how='nunique').compute().plot()
Next stop…Dask
Now that we know why Dask is a popular solution for parallel computing, the next thing to do is getting started with it. Once you install Dask from Conda, pip, or source, you can also look at adding optional dependencies based on specific functionalities. You can find the list of supported optional dependencies here.
To conclude, if you are a fan of Pandas when it comes to big data, Dask will make you fall in love with handling volume of big data hasslefree. Performance, scalability, familiarity, and the popular Python at the core, make Dask a wholesome tool for your data volume-heavy projects.
Looking for more details
Watch this video on youtube
Follow Me on Linkedin & Twitter
If you are interested in similar content hit up the follow button on Medium or follow me on Twitter and Linkedin




